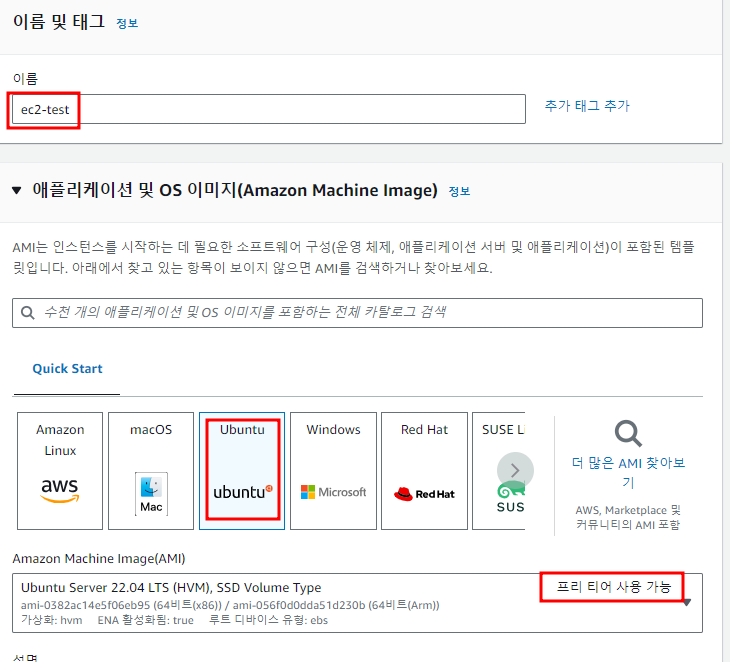
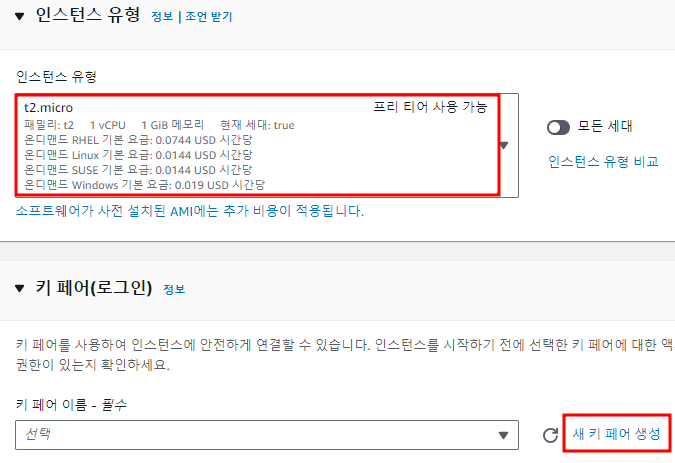
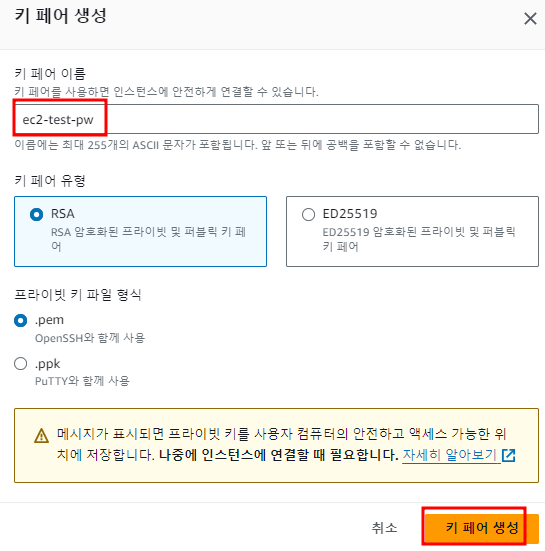
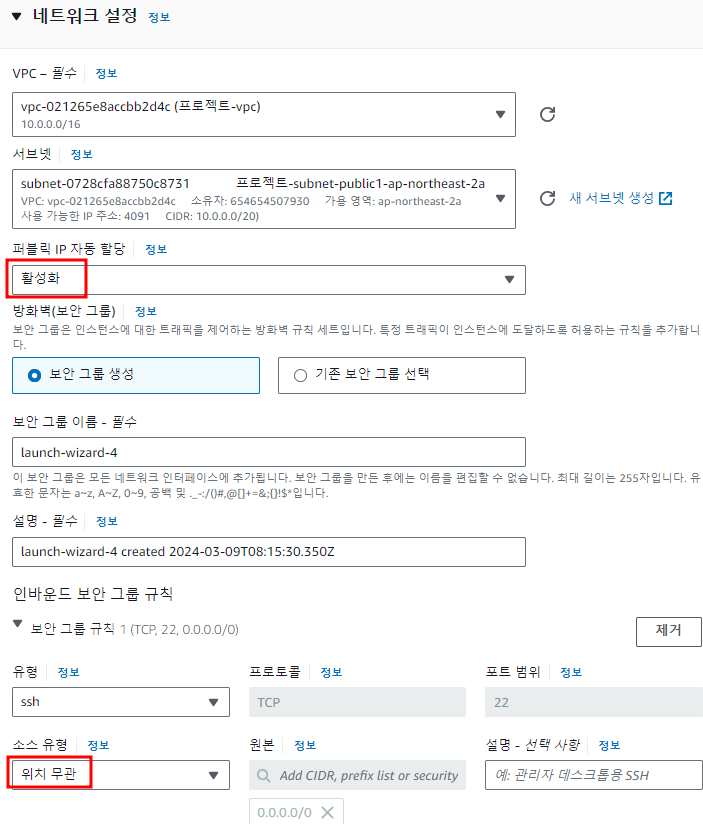
mysql 에서 사용하는 로그들 정리해보자
1. General log
general log 를 활용하면 client 에서 어떤 쿼리들을 mysql server 에 보내는지 확인 할수 있다.
1) Binary log 와의 차이
general log 는 서버에 쿼리 요청이 들어오는 순서대로 로그에 기록된다.
반면 binary log 는 실행시간에 따라 기록이 된다.
또한 binary log 는 select 는 포함하지 않는다.
general log 는 조회 쿼리도 포함되기에 log 의 양이 많다.
2) output 종류 (slow 동일)
아래 log_output 을 아래 세가지 중 하나를 선택할 수 있다.
none 으로 설정을 하면 우선순위가 앞서며 general_log=on 으로 설정해도 로그가 남지 않는다.
- file => *.log 를 생성
- table => *.csv 를 생성
- none
table 을 선택하면 general_log 이름으로 DB에서 조회가 가능해진다.
테이블을 사용하는데 size 가 걱정되어 테이블 사이즈를 조회하는 쿼리를 날리면 0 으로 나온다.
이것은 general_log 테이블이 테이블이라는 object 에 쌓는 것이 아니고
실제로는 CSV 엔진으로 general_log.CSV 라는 파일에 덤프를 쌓고 있기 때문이다.
3) Table output 의 장점
- query 에 조건문을 넣어서 질의 하는 것이 가능해진다.
- 원격에서도 확인이 가능
- csv 파일 접근 가능한 스프레드시트에서 활용이 가능해진다.
4) general log 사용하기
show variables like 'general%';
set global general_log=on;
set global log_output='TABLE';
set global general_log=off
2. Slow log
실행된 쿼리 중 오래 돌았던 쿼리를 기록.
남기는 기준은 long_query_time 파라미터 (min 0, default 10)
사용여부 : slow_query_log = 0 disable, 1 enable
파일이름 : slow_query_log_file=file_name
general log 와 마찬가지로 log_output 이 table 일 경우 CSV 엔진을 사용하여 *.CSV 파일을 만든다.
size 가 커질 경우 조회
3. Bin/relay log
data 를 변경하는 statement 를 기록. select 는 포함되지 않는다.
복제서버 구조에서 source 쪽의 binlog 를 target 에 전달하면 target 의 relay log 에 동일한 포맷으로 기록된다.
로그포맷 형식에는 아래 3가지가 있다.
- Statement-Based Logging (SBL)
- Row-Based Logging (RBL)
- Mixed
binmysqlbinlog
4. Error log
mysqld 를 운영, 중지, 시작시 만나게 되는 에러를 기록
- 기동관련 정보성 및 에러메시지
- 비정상종료 복구 메세지
- 쿼리처리 도중 발생 에러메시지
- aborted connection
max_connect_errors
- innodb모니터링, show engine innodb status 결과
- mysql 종료메시지

이렇게 정리해놓고 봐도 알수있는게 mysql 은 네이밍에 일관성이 없는 것이 특징이다.
'생계 > MySQL' 카테고리의 다른 글
| innodb 사용시 pk 의 선정 (0) | 2024.09.22 |
|---|---|
| mysql 복제 비교 replication , aurora (1) | 2024.09.16 |
| DBeaver 시스템 오브젝트 보기 information_schema (0) | 2024.01.16 |
| mysql login-path 로 로그인하기 (0) | 2024.01.15 |
| 가상머신 virtualbox mysql replication 구성하기 (0) | 2024.01.15 |