SELECT LEVEL, LPAD(' ', 4*(LEVEL-1)) || e.FIRST_NAME || ' ' || e.LAST_NAME AS "Employee", e.EMPLOYEE_ID, e.MANAGER_ID, e.JOB_ID, e.SALARY, e.DEPARTMENT_ID FROM EMPLOYEES e START WITH e.MANAGER_ID = 0 CONNECT BY PRIOR e.EMPLOYEE_ID = e.MANAGER_ID WHERE e.DEPARTMENT_ID = 60 ORDER SIBLINGS BY e.SALARY DESC;
- WHERE 절은 계층 구조가 만들어진 후에 적용. => 상위 관리자가 다른 부서에 속해 있어도(ex. 90) 결과에 포함 - ORDER SIBLINGS BY : 이 구문은 같은 레벨의 형제 노드들을 정렬. 여기서는 각 레벨에서 급여(SALARY)를 기준으로 내림차순 정렬합니다. 예를 들어, LEVEL 4의 Bruce, David, Valli는 모두 같은 상사(Alexander)를 가지고 있으며, 이들은 급여 순으로 정렬됨. - 최상위노드의 manager_id 는 보통 null 이 된다. 그러나 검색 편의를 위해 특정 값을 넣거나 편의상 컬럼을 추가하기도한다. (ex. IS_ROOT )
- prior 에 명시된 컬럼이 상수로 바뀌고 이를 반대편 컬럼(manager_id) 에 넣고 찾아가게 되므로 해당 컬럼에 인덱스를 생성하는 것이 좋다. 역전개의 가능성이 있기에 반대쪽 컬럼에도 인덱스를 생성하는 것이 좋다.
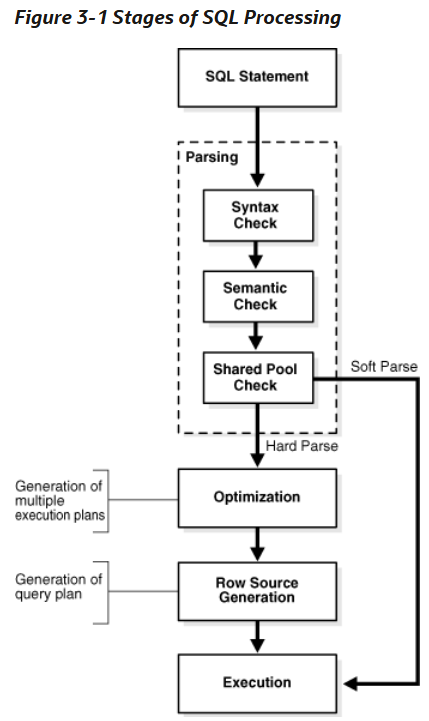
3. shared pool check : 동일한 sql 이 shared pool 에 캐싱되어 있는지 확인
이 과정을 거쳐 SQL 이 캐싱되어 있지 않는 것으로 확인되면 (library cache miss)
4. 실행계획 생성 단계를 거쳐
5. 최종적으로 실행을 하게 된다.
이때 실행계획 생성과정에서 library cache, data dictionary cache 에 반복적으로 접근하고 이 과정에서
latch 라는 lock 보다는 가벼운 잠금장치를 수없이 획득하는 과정을 거친다.
소프트 파싱 vs 하드 파싱
소프트 파싱 (Soft Parsing) 이라는 것은 이미 만들어진 실행계획을 캐시에서 찾아 재사용하는 과정이다.
Shared Pool의 Library Cache에 저장된 SQL 실행 계획을 공유하여 최적화 과정을 생략한다. 실행계획 생성과정이 cpu 를 많이 소모하는 과정이기 때문에 하드 파싱에 비해 더 빠르고 리소스를 절약할 수 있다.
하드 파싱 (Hard Parsing) 캐시에 SQL 이 존재하지 않아 (library cache miss) 새로운 실행 계획을 생성해야 할 때 발.
최적화 및 로우 소스 생성 단계까지 모두 거친 후에 SQL 이 실행된다.
소프트 파싱의 이점과 한계
소프트 파싱은 실행 계획을 반복적으로 생성하는 오버헤드를 줄여 성능을 향상 시켜주어 이롭지만( 특히 OLTP 환경에서 동시 접속자가 많을 때 효과적 ) 항상 최선의 선택은 아니다.
사용자 입력값을 바인드 변수 처리하면 같은 SQL ID 로 처리되어 소프트 파싱으로 처리되는 비율이 높아지지만
SQL 최적화 시점에 컬럼의 히스토그램을 사용하지 못해 실행 계획이 고정 되고 실제 데이터의 분포도가 플랜에 적용이 안되는 경우가 생긴다.
바인드 Peeking의 역효과 예시
다음과 같은 테이블과 쿼리가 있다고 가정해봅시다: sql SELECT * FROM 직원 WHERE 부서 = :dept
이 테이블에서 '영업부'는 전체 직원의 50%를 차지하고, 나머지 부서들은 각각 5% 미만의 직원을 가지고 있습니다. 첫 실행 시 :dept에 '인사부'가 바인딩되었다면: 옵티마이저는 인덱스 스캔을 선택합니다. 이 실행 계획이 캐시에 저장됩니다. 이후 '영업부'로 쿼리를 실행하면: 캐시된 실행 계획(인덱스 스캔)을 사용합니다. 하지만 영업부는 데이터의 50%를 차지하므로, 풀 테이블 스캔이 더 효율적일 수 있습니다. 이로 인해 '영업부' 쿼리의 성능이 크게 저하될 수 있습니다1.
소프트 파싱 한계에 대한 대안
1. 힌트 사용: 특정 쿼리에 대해 옵티마이저 힌트를 사용하여 원하는 실행 계획을 강제 SELECT /*+ FULL(직원) */ * FROM 직원 WHERE 부서 = :dept
2. 아웃라인 사용: 특정 쿼리에 대한 실행 계획을 고정 CREATE OUTLINE 직원_부서_조회 FOR SELECT * FROM 직원 WHERE 부서 = :dept;
3. 적응적 커서 공유 활용: Oracle 11g 이상에서는 적응적 커서 공유를 통해 바인드 변수 값에 따라 다른 실행 계획을 사용할 수 있다
4. 특정 SQL의 소프트 파싱 방지 SELECT /*+ NO_SHARED_CURSOR */ * FROM 직원 WHERE 부서 = :dept
5. CURSOR_SHARING 파라미터 조정:
세션 레벨에서 CURSOR_SHARING을 EXACT로 설정, 해당 세션의 모든 쿼리에 대해 소프트 파싱을 방지 ALTER SESSION SET CURSOR_SHARING = EXACT;
1) 자동 증가: 새로운 레코드가 삽입시 자동으로 고유한 숫자를 생성. 주로 기본 키로 사용, 각 행의 고유성을 보장 2) 초기값 및 증가값 설정 가능: 기본적으로 1부터 시작하며, 각 행이 추가될 때마다 1씩 증가. 3) 데이터 타입 제한: 주로 INT 타입으로 설정, 데이터 타입에 따라 최대값이 제한됩니다. 예를 들어, INT의 최대값은 약 21억입니다 4) 연속성: 삭제된 행의 ID는 재사용되지 않고 건너뛴다.
* mysql 에서 innodb 를 엔진으로 사용할때 auto_increment 컬럼을 pk 사용하는 것이 적절한가?
# 일반테이블의 파티션 전환시 유의점 1. 인덱스 제약: - MySQL의 파티션 테이블에서는 모든 인덱스가 로컬 인덱스로 처리된다. - 글로벌 인덱스를 지원하지 않으므로, 기존 인덱스 구조를 재검토해야 함.
2. 유니크 키와 프라이머리 키 제약: - 파티션 키는 모든 유니크 인덱스(프라이머리 키 포함)의 일부 또는 모든 칼럼을 포함해야 함. 아닐경우 에러남 - 기존 테이블의 키 구조가 이 요구사항을 충족하는지 확인 필수
3. 외래 키 제약: - 파티션 테이블에는 외래 키를 설정 불가 (성능, 관리적 측면의 설계결정) - 기존 테이블에 외래 키가 있다면 이를 제거하거나 대체 방안을 마련 필요.
4. 파일 제한: - 파티션 테이블은 각 파티션마다 별도의 파일을 사용하므로, 서버의 open-files-limit 설정을 적절히 조정필요.
5. 성능 고려: - 파티션 개수가 많아질수록 오히려 성능이 저하될 수 있다. - 특히 INSERT 작업의 경우, 파티션 테이블이 일반 테이블보다 느려질 수 있다.
6. 잠금 처리: - 파티션 테이블에 쿼리 실행 시 모든 파티션에 대해 잠금이 걸린다. - 이는 동시성 처리에 영향을 줄 수 있으므로 주의 필요.
7. 파티션 키 선택: - 효과적인 파티션 프루닝을 위해 적절한 파티션 키를 선택해야 함. - 주로 조회 조건에 자주 사용되는 칼럼을 파티션 키로 선택하는 것이 유리
8. 데이터 마이그레이션: - 기존 데이터를 새로운 파티션 구조로 마이그레이션하는 과정에서 서비스 중단이 필요한지 확인 필요 - 대량의 데이터 이동이 필요하므로 충분한 시간과 리소스를 확보해야 함.
9. 쿼리 최적화: - 기존 쿼리들이 파티션 구조에서도 효율적으로 동작하는지 검토, 필요시 최적화 필요.
이러한 점들을 고려하여 신중하게 파티션 전환을 계획하고 실행해야 한다. 또한 전환 전후로 충분한 테스트를 수행하여 성능과 기능에 문제가 없는지 확인해야 합니다.
# 파티션 테이블 샘플 스크립트 -- 1. 날짜 기반 레인지 파티션 테이블 생성 CREATE TABLE sales ( id INT AUTO_INCREMENT, sale_date DATE NOT NULL, customer_id INT, amount DECIMAL(10,2), PRIMARY KEY (id, sale_date) ) PARTITION BY RANGE (YEAR(sale_date)) ( PARTITION p2021 VALUES LESS THAN (2022), PARTITION p2022 VALUES LESS THAN (2023), PARTITION p2023 VALUES LESS THAN (2024), PARTITION p2024 VALUES LESS THAN (2025), PARTITION future VALUES LESS THAN MAXVALUE );
-- 2. 파티션 관리: 새 파티션 추가 ALTER TABLE sales ADD PARTITION (PARTITION p2025 VALUES LESS THAN (2026));
-- 4. 특정 파티션 데이터 삭제 ALTER TABLE sales TRUNCATE PARTITION p2021;
-- 5. 파티션 삭제 ALTER TABLE sales DROP PARTITION p2021;
-- 6. 파티션 분할 ALTER TABLE sales REORGANIZE PARTITION p2023 INTO ( PARTITION p2023_h1 VALUES LESS THAN ('2023-07-01'), PARTITION p2023_h2 VALUES LESS THAN (2024) ); -- maxvalue 파티션 분할 ALTER TABLE sales REORGANIZE PARTITION future INTO ( PARTITION p2025 VALUES LESS THAN (2026), PARTITION future VALUES LESS THAN MAXVALUE );
-- 7. 파티션 정보 확인 SELECT PARTITION_NAME, TABLE_ROWS, AVG_ROW_LENGTH, DATA_LENGTH FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_SCHEMA = 'your_database_name' AND TABLE_NAME = 'sales';
-- 8. 파티션을 고려한 쿼리 예시 SELECT * FROM sales PARTITION (p2023) WHERE sale_date BETWEEN '2023-01-01' AND '2023-12-31';