CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(10) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin NOT NULL, email VARCHAR(100) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin, age varchar(5) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin, address text collate utf8mb4_general_ci, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin;
-- [G] 1. char set ALTER TABLE users CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; -- [B] 1. char set INSERT INTO users (username, email, age, address) VALUES ('fastlookup', 'fast@example.com','1','L.A santa monica beach');
-- [G] 2. col order ALTER TABLE users MODIFY COLUMN email VARCHAR(100) AFTER age; -- [B] 2. col order INSERT INTO users (username, email, age, address) VALUES ('émilie', 'émilie@example.com','24','jeju-island');
-- [G] 3. col type varchar -> int ALTER TABLE users MODIFY COLUMN age int; -- [B] 3. col type varchar -> int INSERT INTO users (username, email, age) VALUES ('jane_smith', 'jane@example.com', 25);
-- [G] 3. col type text -> varchar ALTER TABLE users MODIFY COLUMN address VARCHAR(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; -- [B] 4. col type text -> varchar INSERT INTO users (username, email, age, address) VALUES ('no_index', 'no_index@example.com','98','new-york,new-york');
블루-그린 테이블 구조가 달라도 데이터는 정상적으로 복제가 되었다.
작업이 완료되었고, 복제가 완료되었으면 staging 을 prod 로 바꾸는 switch over 를 하자
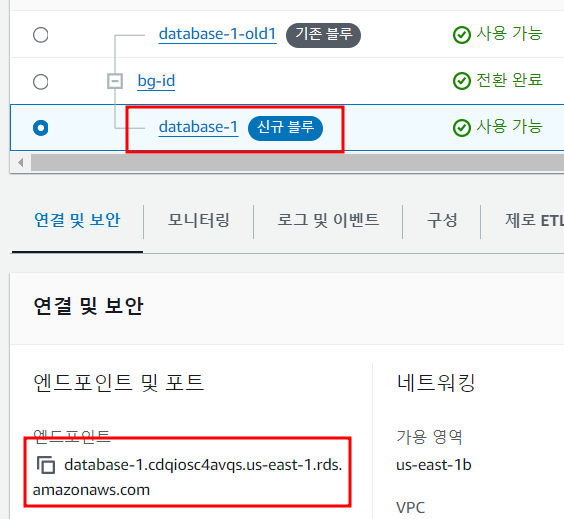
전환이 완료되었다. 그린은 신규블루로 바뀌었고 엔드포인트도 기존 블루의 엔드포인트로 바뀌었다.
기존블루의 인스턴스 이름에는 "old" 가 붙게 된다.
사용자 입장에서는 잠깐의 순단이 발생하고 운영반영이 되었다.
* 스위치오버 전후 유의점
- 전환 전 그린 파라미터의 원복 : read_only, slave_type_conversions ( 재부팅 필요)
# 중요한 상태 항목들 ITEMS_TO_SHOW="Source_Log_File|Read_Source_Log_Pos|Exec_Source_Log_Pos|Replica_IO_Running|Replica_SQL_Running|Seconds_Behind_Source|Last_IO_Error|Last_SQL_Error"
while true do echo "==== $(date) ====" mysql -h "$MYSQL_HOST" -P "$MYSQL_PORT" -u "$MYSQL_USER" -p"$MYSQL_PASS" -e "SHOW REPLICA STATUS\G" | grep -E "$ITEMS_TO_SHOW"
# 복제 지연 확인 SECONDS_BEHIND=$(mysql -h "$MYSQL_HOST" -P "$MYSQL_PORT" -u "$MYSQL_USER" -p"$MYSQL_PASS" -e "SHOW REPLICA STATUS\G" | grep "Seconds_Behind_Source" | awk '{print $2}') if [ "$SECONDS_BEHIND" != "NULL" ] && [ "$SECONDS_BEHIND" -gt 0 ]; then echo "경고: 복제 지연이 $SECONDS_BEHIND 초 발생했습니다." fi
GIN(Generalized Inverted Index) 인덱스란 ? PostgreSQL에서 복합적인 데이터를 효율적으로 검색하기 위해 사용되는 특수한 인덱스 유형 주요 특징은 아래와 같다.
1. 복합 데이터 처리: 배열, JSON, hstore, tsvector 등 복합적인 데이터 타입에 적합 2. 키워드 기반 검색: 문서나 텍스트에서 특정 단어를 빠르게 찾을 수 있다. 3. 역인덱스 구조: 키워드나 토큰을 기반으로 데이터를 인덱싱 4. 전문 검색(Full-text search) 지원: 텍스트 검색 속도를 크게 향상 5. 다양한 연산자 지원: LIKE, ILIKE, ~, ~* 등 다양한 검색 연산자를 지원
GIN 인덱스는 특히 대량의 텍스트 데이터를 처리할 때 B-tree 인덱스보다 훨씬 효과적이며, 검색 성능을 크게 향상시킬 수 있다. 다만, 인덱스 생성과 업데이트에는 상대적으로 많은 시간이 소요될 수 있습니다
## 복합 데이터 처리
테스트 테이블을 만들고 GIN 인덱스 사용 전후의 플랜을 비교해보자
-- Create a table with a JSONB column CREATE TABLE products ( id SERIAL PRIMARY KEY, name VARCHAR(100), details JSONB );
-- Query using the GIN index to find products with specific attributes EXPLAIN ANALYZE SELECT name, details FROM products WHERE details @> '{"brand": "TechCo"}';
-- Query to find products with specific tags EXPLAIN ANALYZE SELECT name, details FROM products WHERE details->'tags' @> '"electronics"'::jsonb;
-- Create a GIN index on the JSONB column CREATE INDEX idx_product_details ON products USING GIN (details);
## 전문검색 처리
-- 문서 테이블 생성 CREATE TABLE documents ( id SERIAL PRIMARY KEY, content TEXT, content_tsv tsvector );
-- 함수 생성: 랜덤 문장 생성 CREATE FUNCTION random_sentence() RETURNS TEXT AS $$ DECLARE words TEXT[] := ARRAY['PostgreSQL', 'database', 'index', 'query', 'performance', 'GIN', 'B-tree', 'full-text', 'search', 'optimization', 'SQL', 'data', 'management', 'system', 'relational', 'ACID', 'transaction', 'concurrency', 'scalability', 'replication']; sentence TEXT := ''; word_count INT; BEGIN word_count := 5 + random() * 10; -- 5에서 15 단어 사이의 문장 생성 FOR i IN 1..word_count LOOP sentence := sentence || ' ' || words[1 + random() * (array_length(words, 1) - 1)]; END LOOP; RETURN trim(sentence); END; $$ LANGUAGE plpgsql;
-- 10,000개의 샘플 문서 생성 INSERT INTO documents (content, content_tsv) SELECT random_sentence(), to_tsvector('english', random_sentence()) FROM generate_series(1, 10000);
-- GIN 인덱스 생성 CREATE INDEX idx_gin_content ON documents USING gin(content_tsv);
-- 통계 업데이트 ANALYZE documents;
-- 검색 쿼리 실행 및 실행 계획 확인 EXPLAIN ANALYZE SELECT id, content FROM documents WHERE content_tsv @@ to_tsquery('english', 'postgresql & index');
주식별자 : PK 업무식별자 : 업무적으로 인스턴스를 구분하는 속성 (논리적 구분) 후보식별자 : 주식별자가 될수 있는 후보 대체식별자 : 주식별자로 선택되지 않은 후보식별자 인조식별자 : 물리적으로 인스턴스를 구분. 인스턴스 추가 기준 알수없다 슈퍼식별자 : 식별자 + 추가 속성(주로 성능적 이유, 안만드는 것이 좋다)
2. 식별자 선정 과정 # 98p
1) 업무식별자 도출 2) 후보식별자 도출 3) 업무식별자가 주식별자로 "적합한지 검토" -> 적합) 업무식별자를 주 식별자로 선정 -> 부적합) 후보식별자 중 주 식별자 " 적합한지 검토" => 적합) 후보식별자를 주 식별자로 선정 => 부적합) 인조식별자를 주 식별자로 선정
우선순위 : 업무식별자 > 후보식별자 > 인조식별자
3. 엔터티 유형별 업무식별자 도출
실체엔터티 : 보통 일시속성이 포함x , 포함 되었다면 순수 실체x ex) 사원E 의 주민번호 + 입사일자 행위엔터티 : 누가(who),무엇(what),언제(when) 등 5w1h 로 따져서 업무식별자 도출
4. 식별자 선택 시 고려사항: - 업무적 활용도가 높을 것 - 길이가 짧은 것 - 대표성을 가질 것 - 불변성 (한번 부여된 식별자는 변하지 않아야 함) - 유일성 (각 인스턴스를 유일하게 식별할 수 있어야 함)